2000+ people have subscribed to the growth catalyst newsletter so far. To receive the newsletter weekly in your email, consider subscribing 👇
If you aren’t familiar with the newsletter and online sessions, you can read about it here
Off to the topic,
When it comes to data, all the evils of data originate from a single source. Charlie Munger, partner of Warren Buffet at Berkshire Hathway, sums it up correctly.
Well, I think I’ve been in the top 5% of my age cohort all my life in understanding the power of incentives, and all my life I’ve underestimated it. And never a year passes but I get some surprise that pushes my limit a little farther. Never, ever, think about something else when you should be thinking about the power of incentives.
That single source of everything evil in life (well, mostly) including evils of data is incentives. Incentives motivate people to show the numbers which look good, even if they don’t mean much. These metrics are usually known as vanity metrics. The reason we put these vanity metrics in PRs and presentations because we love the attention, awe, and recognition that they bring.
As an example, imagine that your promotion is due next month, and you have to report some growth numbers to the top management. You want to get that much-deserved promotion, so you report the numbers that will help you look good and hide the ones that won’t. Is it ethically correct? No. But incentives drive your behavior.
Now let’s ask how feasible is it to lie with data? After all, people have been telling us that data never lies. Well, someone wrote a book over it - how to lie with statistics ;)
But is it possible to create a system so that this doesn’t happen in your organization or team? It is, and I am here to help you with 10 commandments.
So where do we start? Let’s start with something that is the cure of vanity metrics — defining the north star metric (NSM) for your product.
1. North Star Metric (NSM)
NSM of the product defined as one metric that matters for the success/failure of your product.
To understand NSM, let’s take Youtube as an example. What matters for Youtube is people spending time watching videos uploaded by creators. If people aren’t spending time watching videos, Youtube will fail. So the metric that matters most for Youtube is total playtime.
But what does defining an NSM do? It solves a few key problems for the organization:
Every team at Youtube is focussed on moving this one metric up. The conflicts around priorities and projects can be easily resolved because everyone agrees that this is one thing that matters.
You have got one indicator of progress, that the whole company understands. So you can explain to everyone how a new initiative helps make that progress.
NSM holds product teams and other teams accountable. In the case of Youtube, engineers can ask PMs on how a certain feature moves playtime up. This leads to an outcome-oriented culture. The product team isn’t focussed on shipping products, rather creating an impact. Same for other teams.
Now that you know why NSM is important, how does one define the NSM of a product? The secret is asking two questions about the NSM.
Does it represent the value created for the customer?
Is it a leading indicator of success for the product? The success could be revenue, GMV, or anything else.
The answer to both these questions should be a definite yes.
Let’s test the NSM of Youtube on these two questions. Total playtime represents the value created for the customer because if they aren’t playing videos on Youtube, you can’t be sure if Youtube is adding any value for users.
Total playtime is also a leading indicator of revenue. More playtime —> more ads played —> more revenue for Youtube. Higher revenue makes Youtube successful.
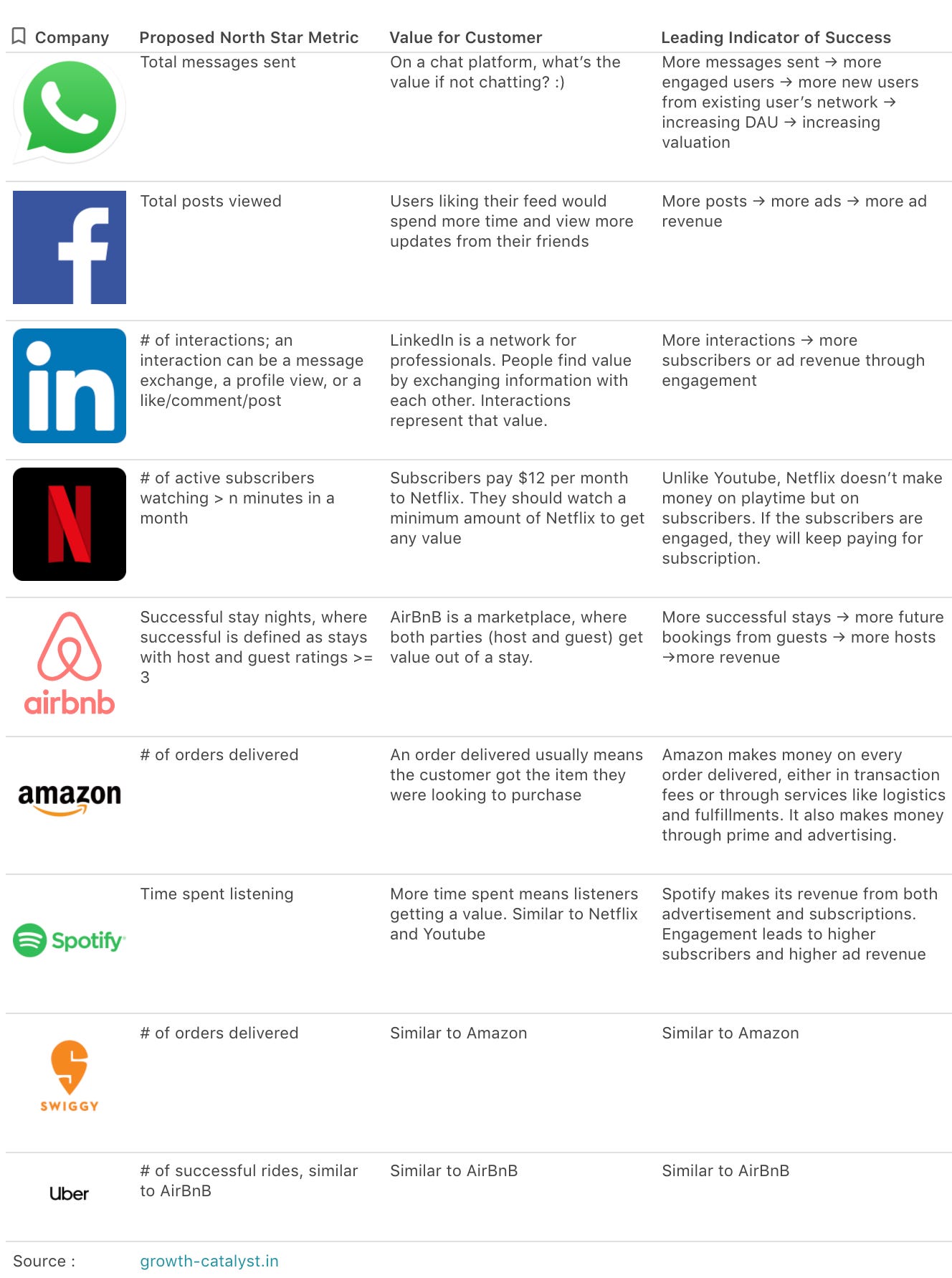
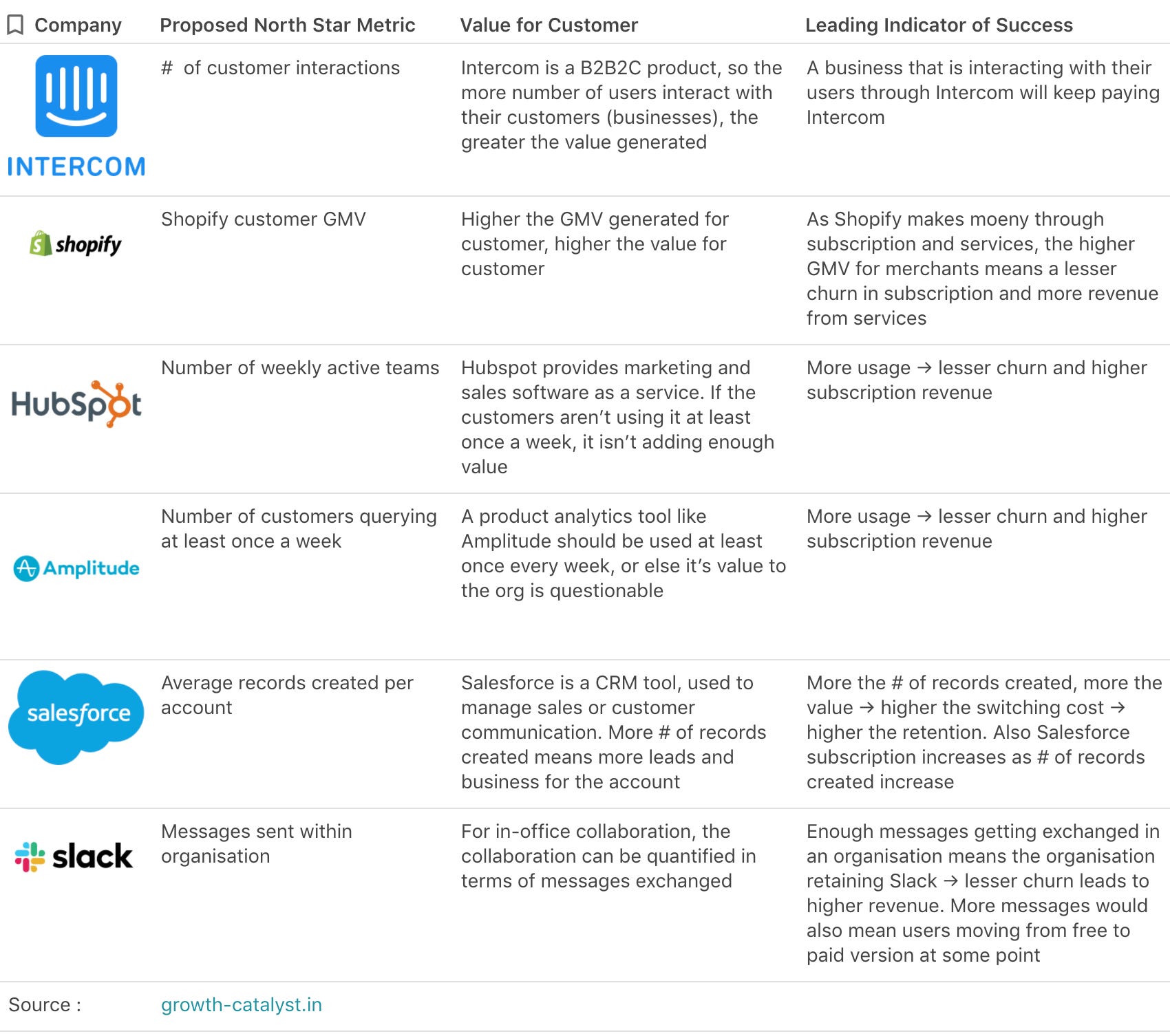
Okay, it holds true for Youtube. What about other products? Is it possible to define the NSM for other products? Let’s look at the north metric of some popular B2C companies.
What about B2B companies? This is what it looks like
So the NSM solves the problem with vanity metrics. However, defining the NSM leads to another problem. Having a single metric to chase can lead to the wrong kind of optimization. There could be possible side effects and negative consequences of chasing only NSM. Also if you have hired a smart team, they might gamify these metrics. Again, incentives!
So how do you solve this new problem? Counter Metrics
2. Counter Metrics
Every critical metric needs to be paired with counter metrics to prevent the wrong kind of optimization. Let’s take a few examples:
# of orders delivered (NSM) has increased on your platform because of discounts offered. So even though your NSM is moving in the right direction, this could lead to bad margins and overall bad business metrics.
Say you are chasing revenue as the NSM. The marketing team has done a fabulous job of bringing users on the platform, increasing the signups, and revenue. But the average revenue per user has dropped, making the whole return in invested capital in marketing negative.
As it’s evident from the examples now, we need to monitor the side effects and negative consequences of chasing a single metric. But how do you define a counter metric? Just take care of the two questions:
How can the NSM be gamified? Identify the metrics to ensure it can’t be gamified and these become your counter metrics.
What are the possible side effects and negative consequences of chasing the NSM? Identify metrics to monitor these side effects, and they become the counter metrics.
Some examples of NSM paired with counter metrics are:
Total watch time — time spent per user
# of orders — average revenue per order
# of customer interactions — total # of customers
I believe that NSM and counter metrics can sort out key metrics for you.
But monitoring metrics aren’t the only thing we do with data. What else do we do with data? We analyze and bring out insights. Any analysis requires us to look at data from all sides and seek out the truth (insights).
Well, incentives can cause bigger problems here. It is difficult to separate a bad analysis from a good one. But don’t despair. There are things that can help you provided you keep the following things in mind.
3. Avoid Confirmation Bias in Analysis
When I first read this quote from Coase, I smiled.
“If you torture data enough, it will confess to anything”
I smiled because it’s so true. Confirmation bias is the tendency to find and interpret data so that it confirms one’s preexisting beliefs or ideas. We often see people finding and presenting trends that confirm their preexisting beliefs and ideas.
“The human understanding when it has once adopted an opinion (either as being the received opinion or as being agreeable to itself) draws all things else to support and agree with it. And though there be a greater number and weight of instances to be found on the other side, yet these it either neglects and despises…”
-Francis Bacon
So what do you do? Simply ask the question for every insight/analysis presented — where can I get the data to disconfirm this? If the answer to the question for analysis is ‘nowhere’, you can trust the analysis. Another thing that Warren Buffet does is to always invite critics in the meeting.
There are other biases besides confirmation bias in data analysis. The important ones to look for are:
Anchoring: Ever found yourself jumping to conclusions or making decisions based on first impressions? This is called anchoring. The information you gain early in your research process could be inaccurate, or may not provide a holistic view of the subject. Slow down, reflect, and ask more questions if you find that you have this habit.
Overconfidence Effect: This is pretty much exactly what it sounds like: It's where you put too much confidence in your own opinions, experience, or knowledge. You may even believe that your thoughts matter more than anyone else's. Combined with other biases, this can lead to poor decision making.
Outliers: Outliers are data points that are far away from the majority (99%) of the data. These are extremely high or extremely low values that can skew the averages, therefore leading to wrong conclusions.
Try calculating the average of your data with outliers included as well as the average without the outliers included. This will show you the difference the outliers are causing.
Availability bias: Availability bias is doing the analysis on the data immediately available to you and not digging in further to get the full picture. Availability bias can be linked to rush-to-solve. If a decision isn’t urgent, dig into your data further to ensure you’re getting the full story from it and not just a piece of the story.
4. Understand the Difference between Correlation and Causation
Let’s define the terms first. Causation means action A causes outcome B. Correlation means A and B are related in some way. Generally, if A and B are correlated, there could be many possible explanations:
A causes B (causation)
B causes A (reverse causality)
A and B are both caused by a third variable, C
There’s another variable involved: A does cause B—as long as D happens.
There is a chain reaction: A causes E, which leads E to cause B
It’s dumb luck or coincidence. They just happen to follow the same trend.
Here is a simple diagram to show correlation and causation (source: towards data science)
What about coincidences?
So we can safely say that all correlations aren’t causations. However, separating correlation and causation is a difficult problem. Correlations are easy to find, causations are hard to establish in real life.
This problem with establishing the causation was used by the tobacco industry back in the 1960s to make the argument that tobacco doesn’t cause cancer. FT wrote an interesting piece over this.
The expert witness giving testimony was arguing that while smoking may be correlated with lung cancer, a causal relationship was unproven and implausible.
The witness’s name was Darrell Huff, a freelance journalist beloved by generations of geeks for his wonderful and hugely successful 1954 book How to Lie with Statistics.
In case you don’t remember this book and the man, scroll back to the top. The tobacco industry kept making this argument for the next few decades until the evidence of causation came in.
In meetings, we often assume causation when we see two events happening together as long as it works in our favor. You may have heard something like this at your work
“We’ve noticed that people who use this feature x during their trial tend to be more likely to convert. How can we get more people to use x during their trial?”
In asking this question, we’re making a big leap: we’re assuming that getting more people to use x during their trial will directly lead to more people converting. We’ve assumed causation — that A causes B to happen — where the data only gives us correlation — that there is a relationship between A and B.
Now there are two ways to avoid this confusion:
Unless causation is clearly defined, assume it’s a correlation and work with it.
Do A/B tests to clearly establish causation. A feature launch through the A/B test ensures that you know how much impact it caused.
5. Law of Small Numbers
One thing that is often overlooked in analytics is the sample size. We have discussed the significance of sample size and error rates in product-market fit.
You should find large # of people participating in your survey. So the question becomes how high should be # of participants (N)? As a rule of thumb, the margin of error in concluding anything from this survey, is ~1/root(N). Here is a table for a better visualisation.
So you should get at least 100-200 responses. The higher # of participants, the lower the margin of error.
The law of small numbers dictates that since the error of margin is high in small samples, you shouldn’t rely on them.
An example of this happens when a person in your team makes the argument that they talked to 4-5 customers and they requested for a particular feature. You should listen to them, but maintain the skepticism that the conclusion is unreliable and you need to verify it with a larger sample set.
Many startups start making critical mistakes because of the law of small numbers. They have a small userbase and then they look at their funnel of this small userbase and make decisions to optimize it. In most of these cases, the conclusions are highly erroneous.
6. Look at Qualitative Data
Nearly all analysis is quantitative i.e. happens on numerical data. The quantitative data tells you often what is wrong. For example, people are adding items to the cart but not placing an order.
There could be multiple reasons why something is wrong. But trusting our intelligence, we make few reasonable hypotheses and build features using those. This is wrong of course. So what’s the right way to find ‘why’ something is wrong?
The most efficient and accurate way of understanding why something is wrong is to talk to users and gather qualitative data. This could be in the form of user interviews or surveys. Remember, quantitative data tells you what’s wrong with your product, qualitative data tells you why it’s wrong.
7. Don’t trust the absolutes, don’t trust the relative
A startup I know did a PR that they achieved 10x growth in the last 12 months. The problem is that they had 100 users 12 months back, and with a 10x growth they still have just 1000 users. When you set the reference point of your choosing, you can show explosive relative growth but it doesn’t mean anything.
So there goes this maxim — “Don’t trust the absolutes, don’t trust the relative”
Usually, the growth rates should be accompanied by absolute numbers.
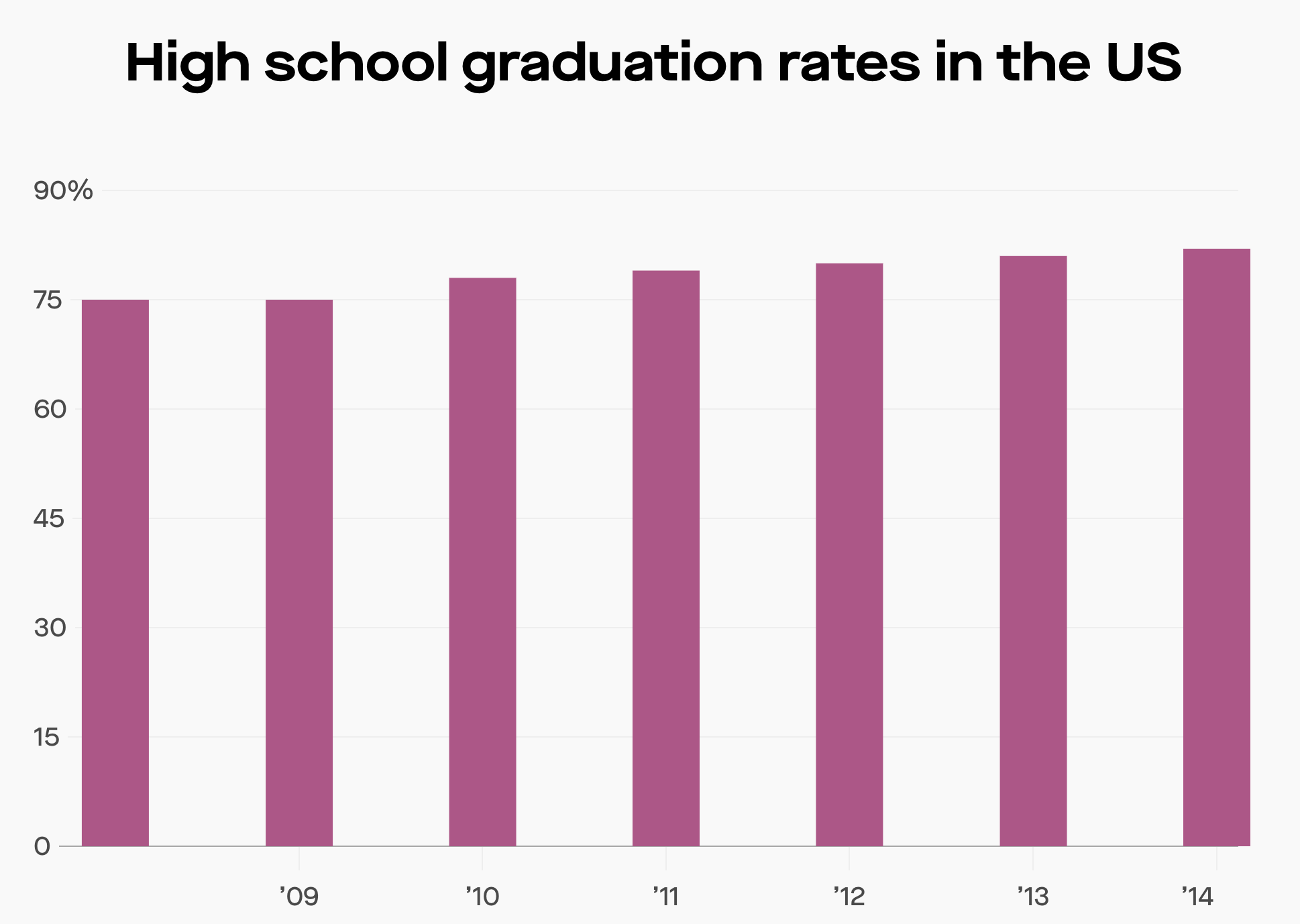
8. Look at the Axes of The Chart, Always!
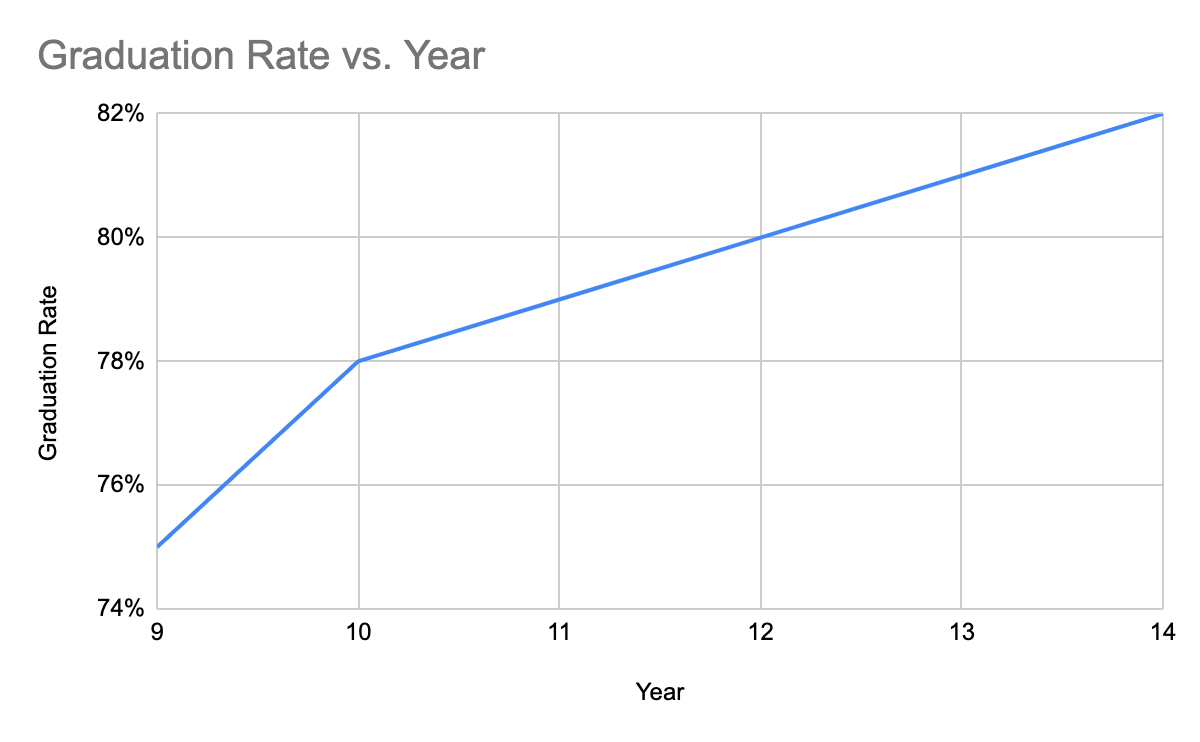
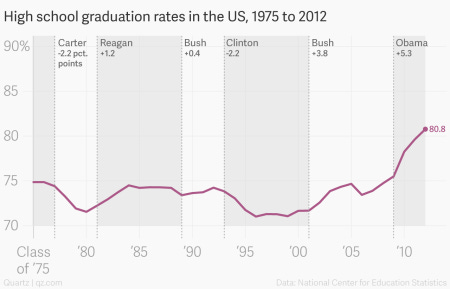
Another way to mislead when it comes to visual charts is by modifying the axes of the chart. There are several ways it’s done. Let’s look at this particular campaign around President Obama which shows the high school graduation rate in the US.
One can argue that using 5 books to represent 75% and 15 books to represent 82% is misleading.
Another way to misrepresent the same numbers is by starting the y-axis at 70% like the one below. The slope of the graph looks steep, implying the growth is amazing.
So what’s the correct way? A correct way to represent the same, which isn’t misleading is
An even better way is to include historical data which gives you the real picture that the graduation rates were already improving in the Bush administration and continued to improve at a higher rate in the Obama administration. Kudos to Obama :)
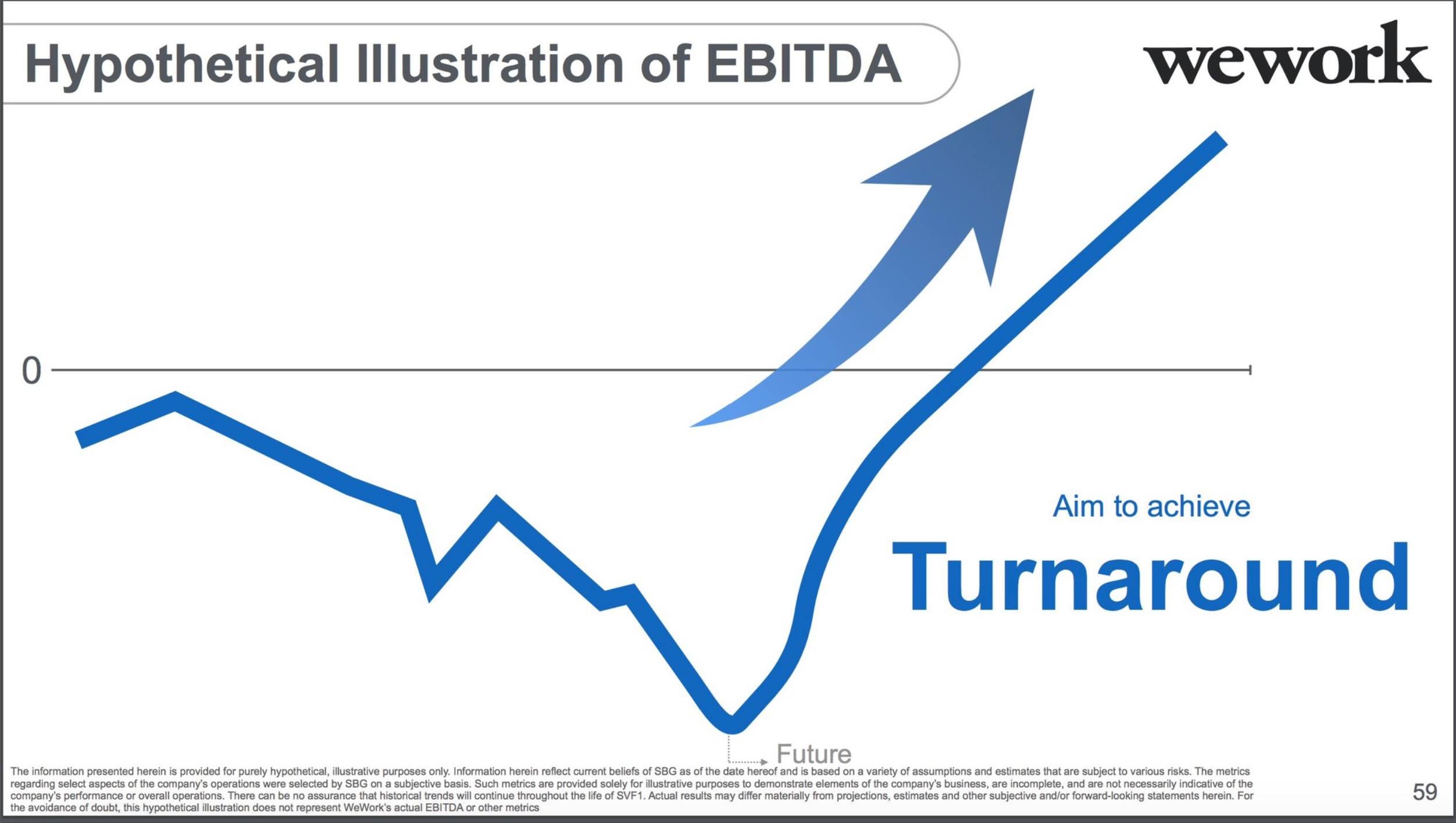
An extreme thing happened in one of the Softbank slides around WeWork back in 2019, where there was no x-axis and y-axis labeling.
The x-axis in this should be Time and the y-axis should be EBITDA here.
By now, you have got a good sense of what pitfalls to avoid while defining the metrics and doing the analysis. The last problem to solve around data is to set up the right process/systems in your team. The last two pointers cover exactly that.
9. Make Dashboards Visible to The Org
You should make data dashboards visible to the org through big screens primarily because of three factors:
A lot of product companies struggle with creating a data-driven culture. Making dashboards visible promotes a data-driven culture. People will start asking for the numbers when they can keep seeing numbers walking around day-in, day-out.
Dashboards make it easy to remember the key metrics of the org. Once people remember the numbers and trends, they start asking questions on why something is/isn’t moving in the right direction.
Because of #2, people will also start asking deeper questions that can be answered through analytics.
Dashboards are quite useful in startups chasing a singular goal. If you have a larger org, it wouldn’t be possible to make dashboards that everyone can understand as it requires some context and everyone is working on a different problem. So in larger orgs, the dashboards can be built on the business unit level.
10. Create an analysis roadmap, just like product roadmap for every quarter
I am yet to see a product org that builds an analysis roadmap. The analysis often comes into picture when we have to answer a particular question. The problem with this approach is that a lot of biases can creep in due to the urgency and importance of the matter. It also is a reactive approach to data where you aren’t using the data to the fullest.
The analysis roadmaps can be quarterly or monthly. What this also means is that you should have a few analysts hired for your team. Many product teams argue that queries can be written by PMs /managers also. Sure! A PM should be capable of doing it, but often a deeper analysis requires a significant amount of time which managers don’t have.
In the absence of analysts, the analysis of data stops. This also means you start missing good insights and trends, which can cost you a lot of time and money later.
So how many analysts are good enough? Depends on data volume and complexity. The data volume and complexity is represented by the cost of analytics tools. Avinash Kaushik, the author of web analytics 2.0, suggested that if you are spending $ x on analytics tools, you should spend $ 9x on hiring analysts (90/10 rule). This suggestion was made in 2006, and you shouldn’t follow it by the book because the analytics tools nowadays have become advanced and also easy to use for different teams.
Just keep a healthy ratio between analytics tool cost and spend on the analytics team, and you will be fine.
This has been my longest post, and for a good reason — my experience in analytics spans the longest and in various industries like management consulting, online classifieds, education tech, video, and game platforms. From these varied experiences, I have created this post and I have a good belief that this will be very helpful to different people and industries.
As the father of the modern quality management, W Edwards Deming said
“In God we trust, the rest bring data”
In an age full of misinformation and misuse of data, whether in elections or otherwise, only the right education around data will save us.
Share it with your friends and colleagues as most will find it useful.







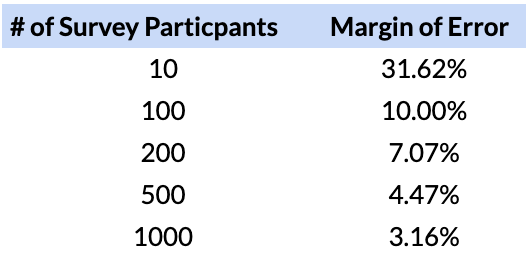

Very well written Deepak! I have bookmarked this and will look to implement learning’s from this newsletter!