3,500+ smart, curious folks have subscribed to the growth catalyst newsletter so far. To receive the newsletter weekly in your email, consider subscribing 👇
If you aren’t familiar with the newsletter and online sessions, you can read about it here
At the heart of any management theory lies the art and science of decision making. In a world filled with opinions and data more than ever, it is hard to convince everyone on decisions that we make as PMs or marketers.
Jeff Bezos, on the other hand, has made many good decisions over the last 3 decades. So it’s refreshing to hear Bezos talking about the decision-making framework in his annual letter to shareholders in 2016. Here is what he wrote,
Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions.
But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.
As organizations get larger, there seems to be a tendency to use the heavy-weight Type 1 decision-making process on most decisions, including many Type 2 decisions. The end result of this is slowness, unthoughtful risk aversion, failure to experiment sufficiently, and consequently diminished invention. We’ll have to figure out how to fight that tendency.
Big companies have ample talent and resources to create new products and markets. Butslowness, unthoughtful risk aversion, failure to experiment sufficiently, and consequently diminished invention leads to them failing in the long run.
But even smaller companies suffer from the problem that he talks about spending too much time on Type 2 decisions. They focus on incremental improvements that don’t make a difference in their survival for a couple of years time.
If you are a senior leader/CEO and understand this with the power to change the culture, it is difficult to manage two competent, smart people with different ideas. You want to empower both and don’t want to operate on your own biases.
That is where doing the a/b tests help
Type 2 decisions: when A/B testing is applied to Type 2 decisions, it’s very easy to walk back through the door as Bezos suggests by simply turning off B and returning to A.
Type 1 decisions: A/B testing helps you understand when a Type 1 decision is needed. If you’re having trouble coming up with a way to test an idea and have the feeling that you won’t be able to roll back the test without consequence, you might be dealing with a Type 1 decision.
Examples? Introducing CTA at the top of the fold versus the end of the page is a type II decision. Testing variants of pricing is a Type I decision, and you should be extremely careful in doing so. Usually, # of type I decisions is much larger than type II, so you don’t have to scratch your head every day 😊
Every company does A/B testing in some way or another. The same way everyone focuses on the culture. But doing it the right way requires something more than hiring someone, and paying for a tool. It requires the right process and principles. We discussed what goes wrong with a/b tests in the last post. They will serve as the principles. In this one, we will discuss what’s the right way of conducting a/b tests. If you follow these methods even as a checklist, it will definitely help you improve the overall decision quality of the teams involved.
If you master them/ have already mastered them, I look forward to meeting you someday and learn :)
Steps to doing tests in the right manner
The whole process can be divided into three parts — before, during, and after the test.
Before the Test
STEP 1: Start talking to customers, stop listening to experts
Most experts offer you something dangerous - the confidence to make a decision based on some anecdote or examples from another company. Nothing wrong with that except you might run into three core problems:
What works for other products won’t necessarily work for yours because your business model, product, culture, or customers are different from anyone else’s.
Markets/ Customers/ Distribution channels are changing faster than ever. Things that worked for you or some competitor yesterday will likely be saturated and far less effective today. Most of the advice is outdated that way
There are no silver bullets. No easy secrets to reach the stars. If it were that easy, everyone would do it :)
Instead, start talking to your customers you are building it for. It will give you the right kind of information and confidence to make decisions. In the next post, I will discuss at length how to talk to customers and generate ideas/insights. Subscribe here to receive it in your inbox if you haven’t already
STEP 2: What are the key problems/questions?
If we talk to your customers, we will be able to come up with a list of customer problems
The unknowns of a product can also be framed as either a question or a problem. For example,
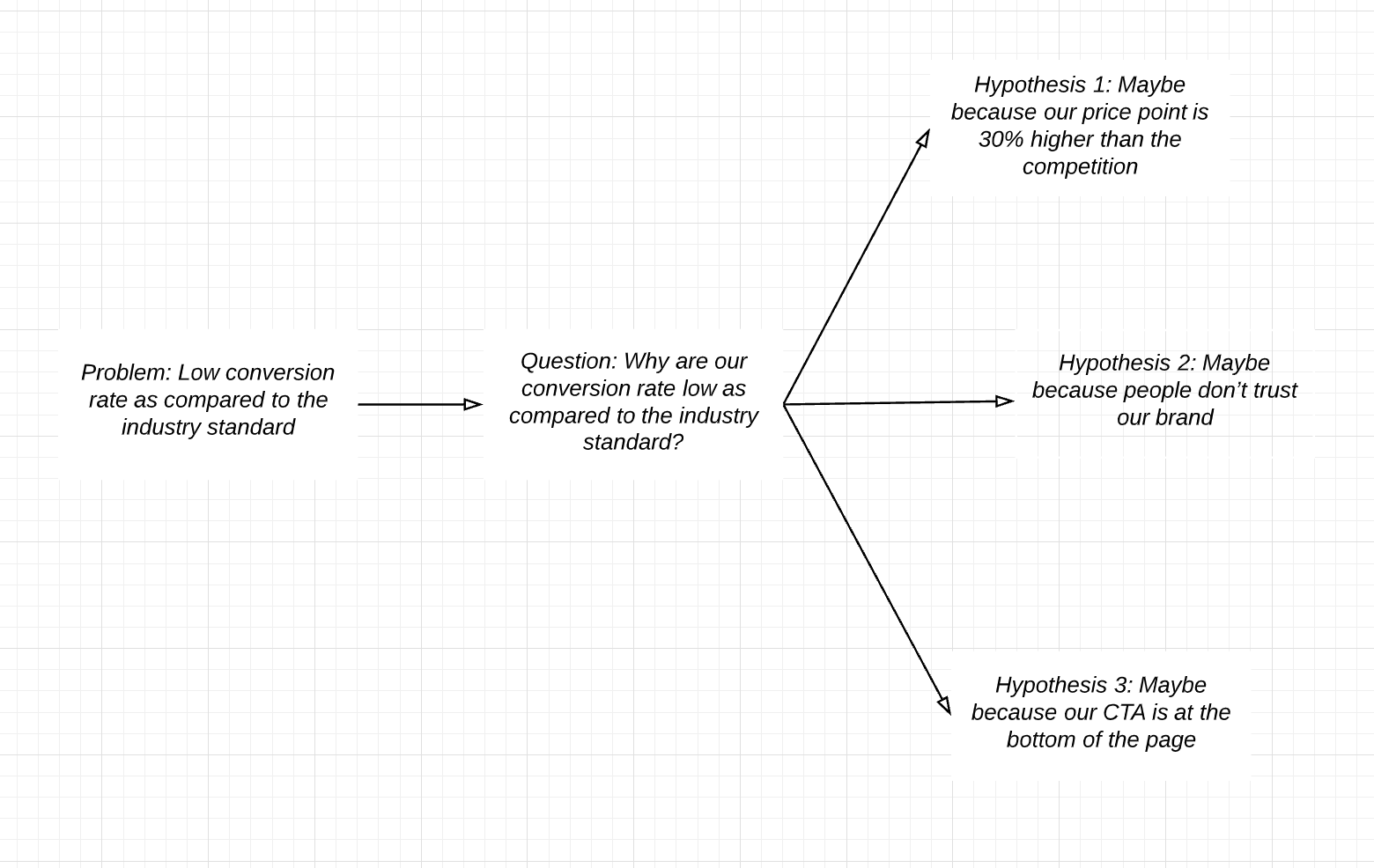
Low conversion rate as compared to the industry standard is a problem
High bounce rate on the landing page is a problem
User not able to find the right information to make the purchase is a problem
Though it’s not a prevalent problem, some teams jump from problems to ideas directly like,
Problem: Low conversion rate as compared to the industry standard
Ideas: we should offer discounts to the first time users, we should change the copy and image on the landing pages, etc.
Don’t do it. There is a subtle, yet powerful step in between — asking questions. All problems can be framed as questions
Why do we have a low conversion rate compared to the industry?
Why do we have a high bounce rate on this page?
Why are users not able to find the right information to make the purchase?
You will see how it helps in the next step.
Optional with step #2: Identify product themes
You can combine the problems into product themes. It helps you pick areas to focus on. This is especially important for startups/ small companies. You shouldn’t do experiments all over the place at once. In a quarter, focus on moving metric around one theme — acquisition, activation, retention, revenue, referrals. This way, the experiments will build on each other, create insight and depth of understanding in an area. They can also be connected to the broader product strategy.
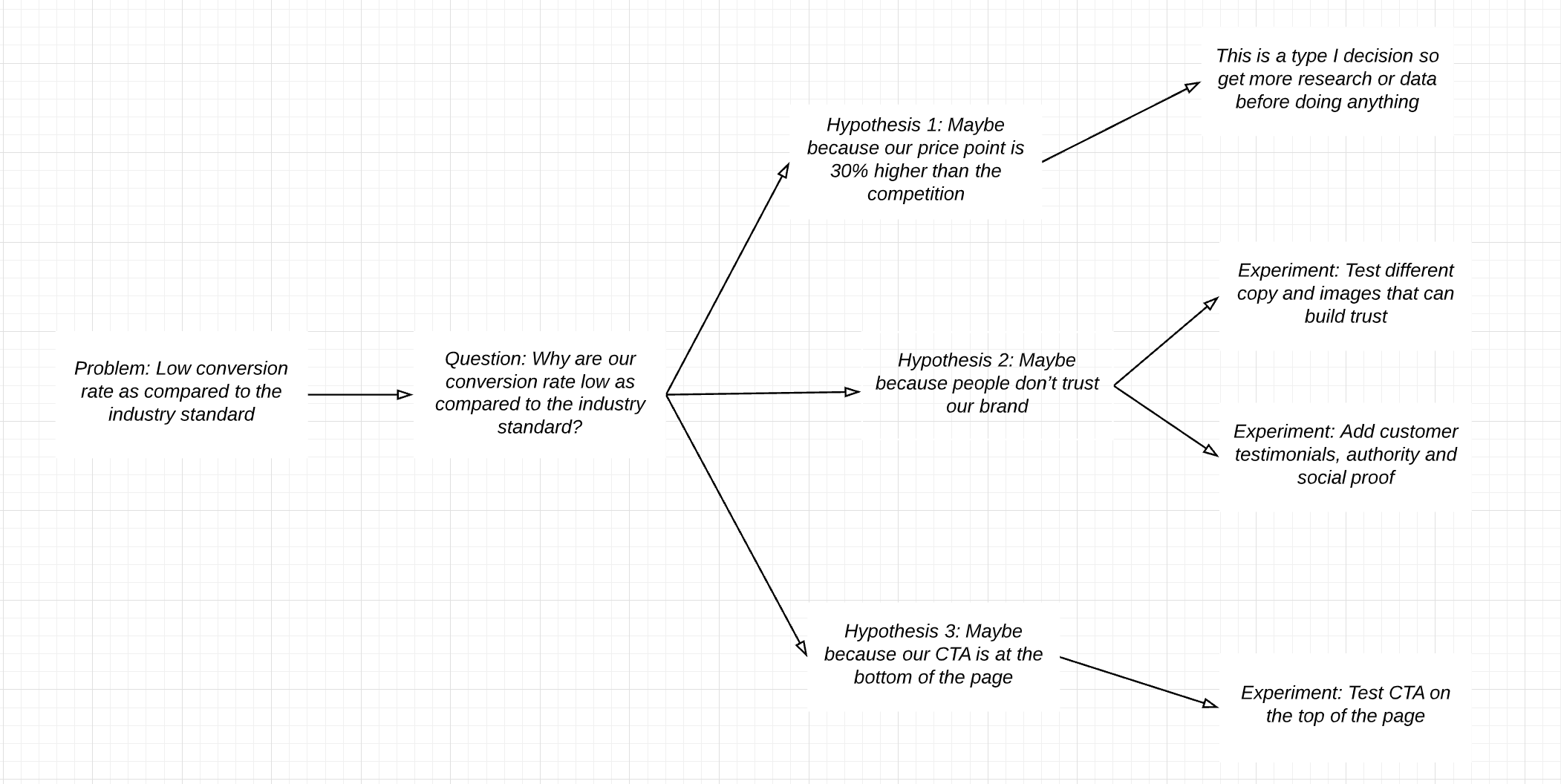
STEP 3: Build questions - hypothesis- experiments
When you ask a question, you can come up with an exhaustive list of hypotheses for that question. Jumping directly from problems to ideas is usually incomplete that way.
Sorry for writing maybe so many times 😁 I want to ensure that you remember that all these are hypotheses and don’t be too sure of yourself.
Now you can move to the last part — defining the experiments to test these hypotheses.
One key issue that you may face at this step is too many hypotheses. Since everyone loves their hypotheses and ideas to test it, the only solution is to ask people to back it either with data or customer interviews.
If you are having trouble generating hypotheses, my next post on how to generate hypotheses/ideas will help you :)
STEP 4: Define success metrics up-front
Good experiments define success up-front. There are three benefits of defining success up-front:
You will properly instrument the metrics associated with the definition of success. Bad experiments get restarted because the right metrics weren’t instrumented from the beginning.
Bad experiments add many metrics to the dashboard, then cherry-pick the ones that improve. The teams will do analysis in endless ways to find a positive data point that can be used to justify the experiment. As the saying goes “If you torture data enough, it will confess to anything”. Avoid this at all costs.
Defining success upfront becomes a learning opportunity. Defining success upfront requires deep thinking about the problem and hypothesis. Once the experiment is over, you see the gap between what you predicted and what actually happened, and that builds your product/growth instincts.
This step also comes with a disclaimer: your org should be forgiving of failure to some extent. You can’t hold people accountable if the success metric doesn’t move as predicted. That said, no org is comfortable with 100% failure rates. Establish what level of failure is acceptable. If you are looking for benchmarks, 50% is a good place to start.
STEP 5: Track counter-metrics
Consider trade-offs while designing experiments. The whole product is a system and if you change some part of the system, it can affect other parts that aren’t directly visible.
For example, if you move up registrations, the registration-to-conversion (counter metric) may go down. Monetization features and ads often lead to some loss of retention and engagement (counter metrics).
Badly designed experiments focus on their own success metrics. They treat every improvement as a win, even if that win came at a cost elsewhere in the system.
Good experiments define counter metrics to make sure it doesn’t cost you more than you are gaining as a system.
Statistical Significance and How Long The Tests Should be Run
After the Experiment
As long as we don’t torture data to confirm our biases, we should be fine. Keeping these pointers in mind also helps.
Improvement in one part of the funnel
Improvement in one part of the funnel doesn’t lead to an improvement in the whole. Sometimes, you see the signups increase which doesn’t lead to an increase in conversions.
It’s a very normal thing. Because you changed something, people got interested in signing up. But this may or may not lead to any improvement in conversions/revenue.
This is especially true about transaction apps like eCommerce, SaaS, etc. Attention apps like Facebook or Instagram operate differently. Their increase in sign-ups mostly leads to good improvement in metrics down the funnel-like time spent and retention. Similarly, a one-time purchase doesn’t lead to changes in retention.
This is why you shouldn’t equate wildly popular Facebook/Google growth stories around the color and size of a button to a transactional app.
Newness effect
I thank Ram, a friend and colleague, for bringing this point to my notice. The “Newness” effect is users clicking on the variant more often because it’s new. For example, 10% at the start of the experiment, tapering off over a few days. It matters because we might make a decision to go ahead with a variant which has a higher conversion rate compared to control in the first week, but lower than control beyond that.
Variant true conversion rate (CvR) in long term: 1%
Original (constant ) CvR: 3%
This could result in performance that looks something like this over time:
Most tools show the average conversion rate (in red). Note that the average conversion rate takes a very long time to approach the true conversion rate of 1% (day 8 in the graph).
Some tools like Google Optimise provide the solution to it by looking at how consistent/variable conversion rates are over time. They take it into account while showing the results. If you using some tool for a/b testing, is important to see whether the tool accounts for the newness effect.
Consequential changes (type I decisions or major launches)
You should monitor the success metrics and counter metrics for some time even after 100% rollout.
You should also keep an active eye on customer sentiments on social media/ reviews beyond the usual metrics.
Best Practices: A Tool of Learning to be a Super Product/Growth Person
A/B tests should be used as a tool for continuous learning. To do that, we need to document the questions, hypothesis, results of the experiment.
Documentation
You could use google sheets for documentation, or some of the advanced tools like Notion. Sharing this with other groups should be mandatory.
Learnings
“What do we do next with what we learned?” is a good place to start. Simply looking at metrics won’t help with learning, rather asking these question and documenting them helps
— Why did it work or not work?
— Does this prove or disprove our hypothesis?
— Was it a good test of the hypothesis? Any alternatives that we missed?
— If it failed, is there a chance that it could be successful if we invest more?
— If it succeeded, should we do more on this to make it even more successful?
I started this post with Bezos's framework for decision-making. I will wrap it with one of the paragraphs in the letter where he talks about experiments.
One area where I think we are especially distinctive is failure. I believe we are the best place in the world to fail (we have plenty of practice!), and failure and invention are inseparable twins. To invent you have to experiment, and if you know in advance that it’s going to work, it’s not an experiment. Most large organizations embrace the idea of invention, but are not willing to suffer the string of failed experiments necessary to get there. Outsized returns often come from betting against conventional wisdom, and conventional wisdom is usually right. Given a ten percent chance of a 100 times payoff, you should take that bet every time. But you’re still going to be wrong nine times out of ten. We all know that if you swing for the fences, you’re going to strike out a lot, but you’re also going to hit some home runs. The difference between baseball and business, however, is that baseball has a truncated outcome distribution. When you swing, no matter how well you connect with the ball, the most runs you can get is four. In business, every once in a while, when you step up to the plate, you can score 1,000 runs. This long-tailed distribution of returns is why it’s important to be bold. Big winners pay for so many experiments.
We should remember this when you think about experiments next time — go for the upside, minimize the downside. Be bold wherever possible 💪
Sneak Peek into the next post
In the next post, we will cover
Methods to generate questions/hypotheses/ ideas around for experimentation
Debates around a/b tests: Algorithms in a/b, should tests be used to resolve conflicts, local maxima problem, etc.
Did I miss something? Please share your feedback/advice directly on LinkedIn/ Twitter. Alternatively, give a shoutout if you really liked it so that this free resource can reach others for learning 🙏🏻
Subscribe here to receive the weekly newsletter in your inbox so you don’t miss it




Superb in-depth Teaching Deepak😊
Learning.Many Thanks.