The last few weeks have been crazily busy, but that shouldn’t deter us from writing and learning. That said, you can always provide me some extra motivation by sharing it on social media if you like the post 😉
If you don’t like it, please share your advice/feedback on how to improve it 😁
Off to the topic — in the last post around A/B testing, we covered the basics. It’s time to dive into the really interesting parts.
More than 3,500 people have subscribed to the growth catalyst newsletter so far. So consider subscribing to receive it in your Inbox👇
In the 1980s, Pepsi launched an advertising campaign to remove Coke from its No. 1 “cola-spot”. The ad showed that in a double-blind taste test, consumers preferred a sip of Pepsi vs a sip of Coke nationwide. They called it the Pepsi Challenge.
This blind test was a way of a/b testing two variants of soda, Coke and Pepsi.
Coke panicked. They put a lot of time, effort, and money to launch a sweeter version of Coke and called it New Coke. But sales went down for Coke, and Pepsi recorded the highest growth during New Coke’s first month.
Interestingly, Coke’s consumers were furious too. Over 400,000 letters of complaint came to the company. As it turns out, people only preferred a ‘sip’ of Pepsi because it was sweeter. But in their homes, while sitting in front of the TV and consuming a whole bottle of Cola, most people still preferred the old Coke and not something sweeter like Pepsi.
This is a great example of the limitations of scientific tests. They might reveal something, which when extrapolated might not be true at all. In a sip, they might prefer Sweeter Cola Pepsi but when it comes to consuming the whole bottle, they would go for Coke.
Such limitations fail the companies and are quite expensive. Hence when it came to writing about A/B tests, I preferred starting with the limitations.
Limitations of A/B Tests
We are all born with limitations, so why do we expect otherwise from A/B tests. Maybe because we don’t understand them fully, or maybe because the experts use the term ‘scientific’ too often with A/B tests. And how dare we question something scientific? 😊
So I am here to tell you that A/B tests have limitations, three in particular. These limitations arise mainly due to the way we run tests and the way we interpret them.
1. Short-term vs Long-term
It is hard to judge the right long-term behavior of the users. As most A/B tests only run only for a couple of weeks, they are almost always telling about the short-term behavior, but not the long-term ones.
An example of this which all of us have faced in our lives is the sales pitch. Sometimes, a company will use a sales pitch to create a sense of urgency for users, making false claims, and converting them into paid users. In a couple of business cycles, metrics like conversion and revenue would go up.
But give it a long enough time, and the problems with conversion will start appearing due to bad brand perception the sales team has created. In this situation, you can avoid this by devising counter-metrics like customer satisfaction rate along with conversion rates.
But normally it’s hard to do which is why I have put it in the limitations section. An example could be Facebook which is one of the biggest advocates of A/B testing. They have done some amazing things for the world through multiple products. But as for the blue Facebook (facebook.com), the product would have evolved into something different and our generation would still have loved it if they hadn’t relied solely on short-term CTRs on PNs, monetization, and engagement metrics.
Generally speaking,
A notification with a high CTR in the first month
A post with a high # of likes
A promise on the landing page that converts users at 2x rate but is hard to deliver in future
All of these will have a terrific success rate with A/B tests in the test duration (2-4 weeks), but whether they will create success for your product in the long-run is a hard question to answer and worth pursuing.
2. The Future Cohort of Users
“If you build it, they will come” is a half-truth of product development.
“If you build it and can reach some of them who love it, the rest will follow” should be the motto ✌️
The second limitation of A/B tests is that they don’t account for a future cohort of users. You can’t reach the users who haven’t downloaded and using your app right now. This is why PMs and marketers are puzzled when a strong hypothesis doesn’t work in tests.
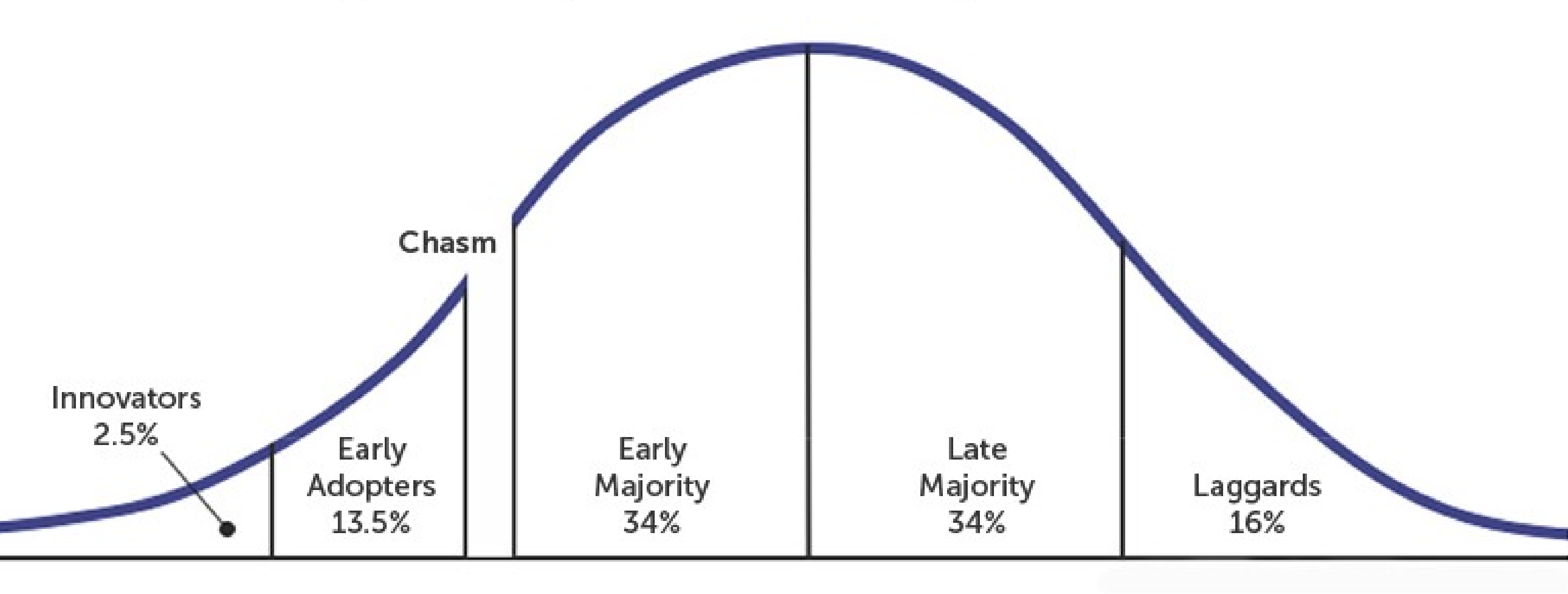
The mistake that we make here is extending the results of an A/B test indefinitely into the future. In the future, the cohorts for which the test will work might join. This is especially true if you are in the early stages of product-market fit and haven’t reached all kinds of users. Look at this graph we discussed in GTM Strategy: Understanding Channelsand figure out if you have covered all kinds of users
Consumers display different behaviors when it comes to the adoption of a new technology/product.
Specifically, the consumers can be divided into 5 parts on the basis of the ease of adoption. He calls them innovators > early adopters > early majority > late majority > laggards. There is a chasm between early adopters and the early majority, and if a product can’t cross this chasm, it will fail. Hence the name of the book “Crossing the Chasm”.
What we should be doing instead is looking at a hypothesis and understanding why it didn’t work.
Tests can often fail because of seasonality, or because you missed one tiny nuance, or because you don’t have the set of users for whom it will work.
You can avoid this to some extent by keeping a backlog of all tests and revisiting them periodically. Re-testing ideas should be an inherent part of a/b testing.
3. The Unchanging World View
A/B tests also assume an unchanging world view. The same people who were uncomfortable with snapping few photos a few years back are making Tik-Tok videos now. The world of technology and associated user behavior changes fast. We should always keep that in mind.
Some of the worst ideas of the 1990s internet bubble have worked very well in the last decade. Grocery shopping where WebVan burned $800 million trying to deliver fresh groceries to your door in the 90s, we have success stories like Swiggy, Bigbasket, Amazon Fresh, and Instacart today. Internet-based currency and pets.com which failed miserably then, are doing pretty well now with cryptocurrency and chewy.com.
The bigger, billion-dollar ideas will take decades to work because they require a big shift in behavior and technology. The smaller ones that you are experimenting with might work in some form in a year from now on the same cohort of users.
The world is constantly changing, and that’s why re-testing becomes important to remove this limitation.
Beyond limitations, there are few things to keep in mind before starting an A/B test. There are a couple of assumptions that we make while reading the results of A/B tests. We should ensure those assumptions are right, or else we will end up looking at wrong results and making decisions — this would be worse than not doing a/b tests at all. It is important to maintain the sanctity of a test — the next section covers two important points.
The Sanctity of a Test
1. Dividing Users into Uniform Cohorts
When you are comparing the results of an a/b test, you assume that the group that saw version A is similar to the group that saw the version B.
While assigning randomly to a wide userbase, it may happen that a particular set of users are over assigned to one version.
Imagine building a gym app for a gym you run. One of the features of this gym app is that users can log their meals. Everyone who has a gym membership can log in to the app. There are two sets of users on this app —
gym rats who come to the gym every day
gym enthusiasts who get the membership but don’t visit often
Your goal is to improve the meal log rates so that you can help more members get to the right meal and exercise.
So you launched a reminder notification that reminds users every day at 9 pm to log their meals. You want to a/b test this notification. A month into the test, here are the results.
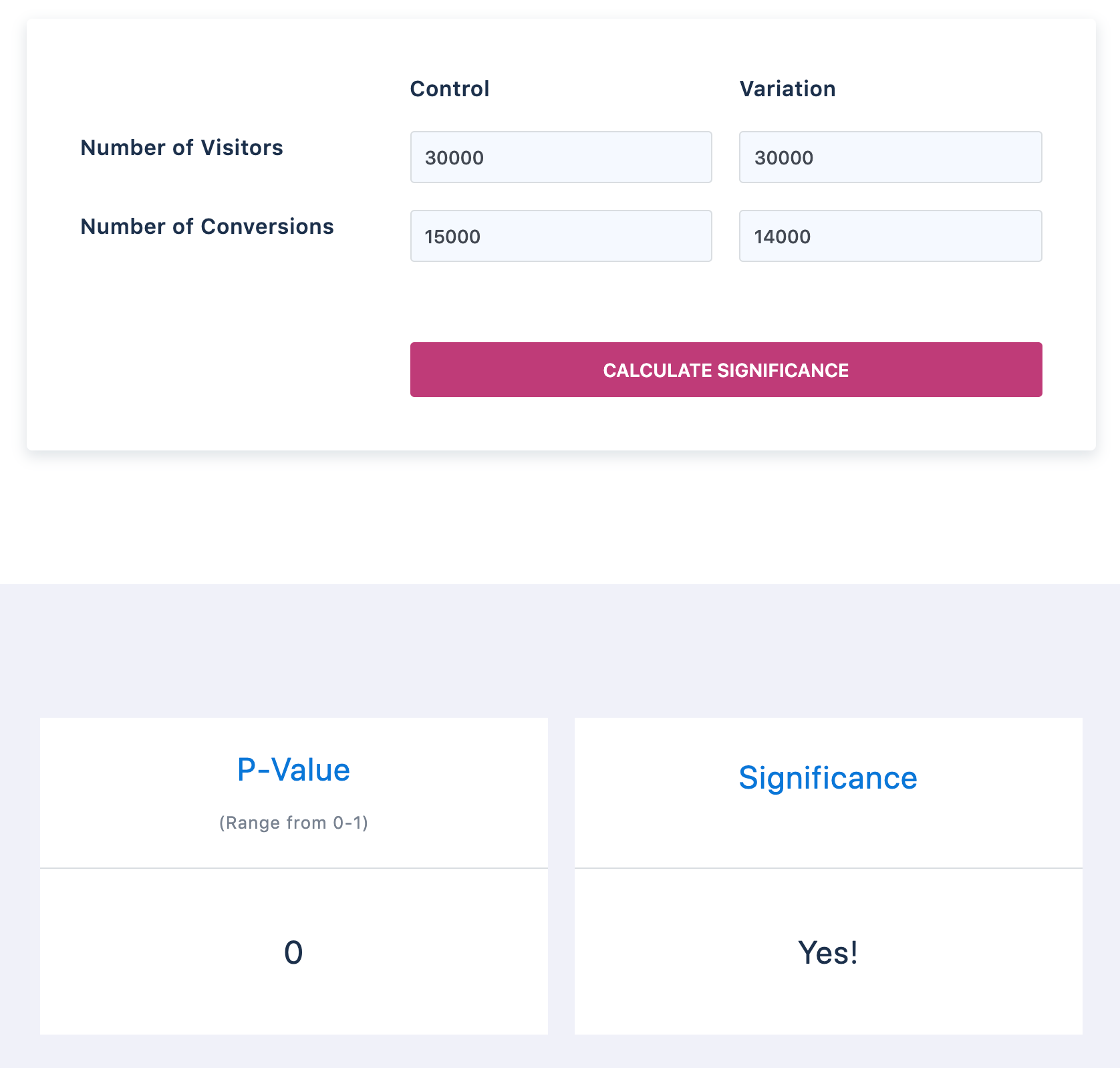
So you are now puzzled that the meal log rate has gone down because of notification. You check the significance of results and they look statistically significant.
So should you conclude that the notification is leading to a lesser # of meal logs? Not necessarily. Let’s check the segments now
As you can see, the meal log rate in both segments has increased to 90% and 41.9%, but due to the wrong random assignment, version A is showing better results than version B.
Dividing consumers into uniform cohorts is very important to maintain the sanctity of the test.
One quick way to measure whether your tool is diving users into uniform cohorts is doing an AA test.
An A/A test puts two exactly identical versions against each other instead of two different versions under A/B testing. If your testing tool is working well, there should be no difference between your control and variation versions. If there is a difference, time to stop all tests before you correct it.
Another thing you should ensure is tight exposure groups. Users in the control group shouldn’t be exposed to the change at any time during the test. If that happens, it will spoil the data.
2. Statistical Significance and How Long The Tests Should be Run
We all understand that reaching a statistical significance is important. Seeing the results early on before they reach significance and concluding either way, is no different than watching the first 10 minutes of the game and concluding which team will win the match. You may be right in few cases because of sheer dumb luck, but that’s not scientific by any measure.
Most of the teams I know hold this rule of statistical significance pretty well.
However, there is another question on similar lines — when should we stop the test? The simple answer is “when it reaches significance”.
The significance calculation makes a critical assumption that you have probably violated without even realizing it: that the sample size was fixed in advance. If instead of deciding ahead of time, “this experiment will collect exactly 1,000 observations,” you say, “we’ll run it until we see a significant difference,” all the reported significance levels become meaningless. This result is completely counterintuitive and all the A/B testing packages out there ignore it.
He argues that whenever a test reaches statistical significance, we can’t call it. So when do we call it complete? We need to answer two questions to find the right answer.
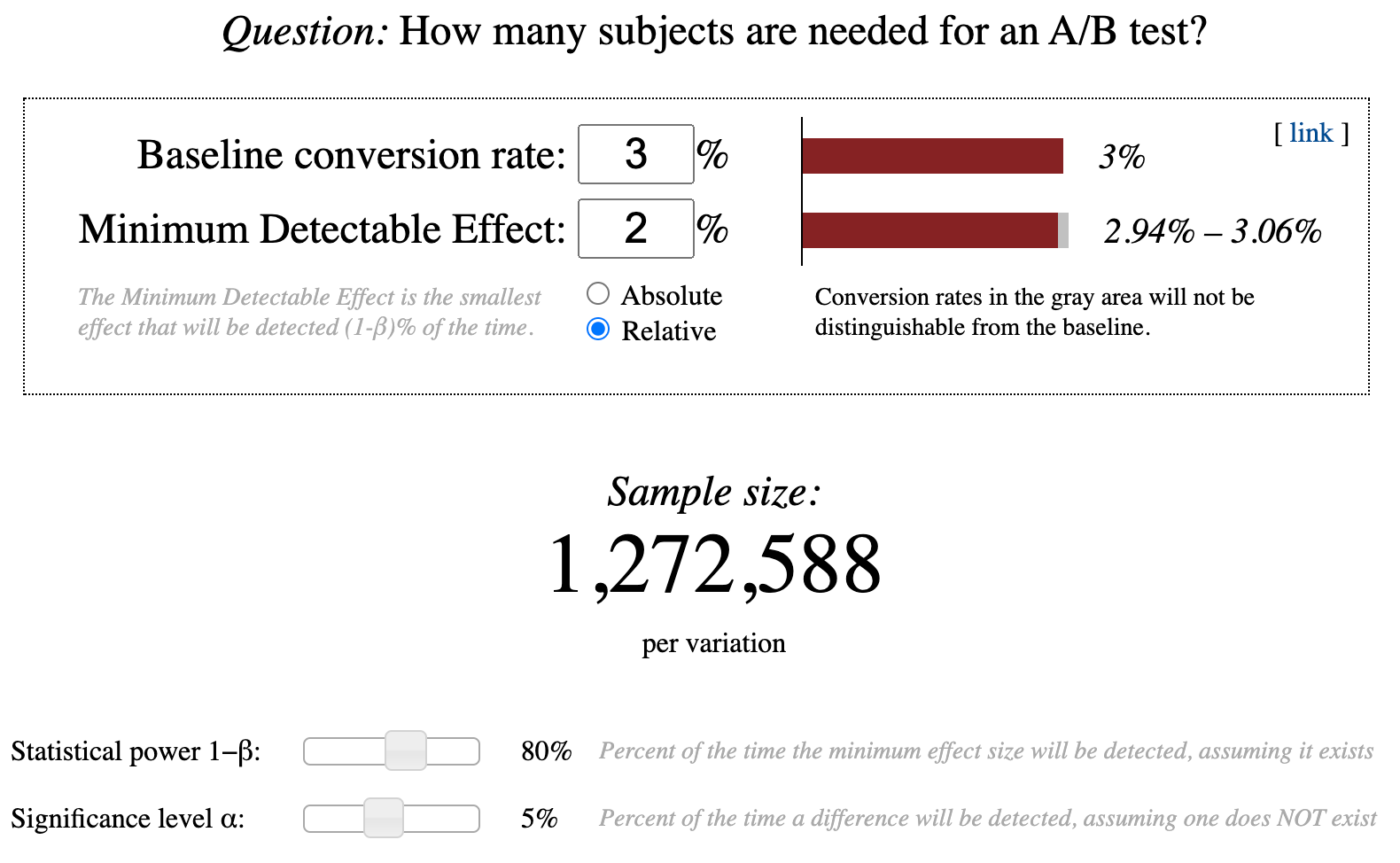
Question 1: How many users are needed for an A/B test?
We need to determine the sample size for the test before conducting the test, also known as the predetermined sample size. This can be done by using many tools out there and requires a baseline conversion rate and minimum detectable effect (MDE) as inputs.
The baseline conversion rate is the current conversion rate.
MDE is the smallest effect that we want to detect.
Let’s take for example a calculator from Evan Miller. Say we have a conversion rate of 3% and want to MDE of 5% relative change. The users needed for the test are 204,493 as shown in the image below from Evan Miller calculator.
I will not go into details but remember that 0.2 and 0.05 are conventional values for β and α and should be used in experiments. You can read more about it here
What if we want the MDE to be 2%?
So using the baseline conversion and MDE, we should find out the minimum sample size and complete the test only when the minimum sample size has been attained. If it does, the test isn’t valid.
Question 2: How long should we run the test?
As long as you need to reach a predetermined sample size. But the longer a test is running, the more susceptible it is to sample pollution. For example, visitors might be deleting their cookies and end up re-entering the A/B test as a new visitor.
Letting your test run for too long bad as well. Usually, it shouldn’t exceed a month.
If you are a small startup with 100s of visitors a day, you probably won’t reach the sample size in a month if your MDE is small. So focus on launching big things and other optimizations. We will cover more about this in the user research post.
Is there a minimum time for which the test should be run?
As a rule of thumb, it is dependent on the consumer cycle.
Take an example of engagement apps like Tiktok and Instagram, you can conclude the tests early as soon as you reach the pre-determined sample size because the engagement cycle for most users completes in hours and days.
On the other hand, transacting apps like Amazon might need more time because they need to account for all buyers including “I need to think about it” buyers, all the traffic sources, and other anomalies like the day of the week, etc. In transacting apps, a good rule of thumb that Shopify provides in two full business cycles.
I will end this post with one last point that should be remembered at all times while designing and conducting the experiments. It is as important as the other points mentioned above.
Bonus Point - Finding Causation instead of Correlation in Tests
Between 1500 and 1800, about 2 million sailors died of scurvy. Today we know that scurvy is caused by a lack of vitamin C in the diet, which sailors experienced because they didn’t have adequate supplies of fruit on long voyages. In 1747, Dr. James Lind, a surgeon in the Royal Navy, decided to do an experiment to test six possible cures. On one voyage he gave some sailors oranges and lemons, and other alternative remedies like vinegar. The experiment showed that citrus fruits could prevent scurvy, though no one knew why. Lind mistakenly believed that the acidity of the fruit was the cure and tried to create a less-perishable remedy by heating the citrus juice into a concentrate, which destroyed the vitamin C. It wasn’t until 50 years later when unheated lemon juice was added to sailors’ daily rations, that the Royal Navy finally eliminated scurvy among its crews. Presumably, the cure could have come much earlier and saved many lives if Lind had run a controlled experiment with heated and unheated lemon juice.
The good thing with A/B tests is that they are controlled experiments in general. The problem that happens sometimes is in the interpretation as it happened in the case above.
How do we make the right interpretation? An experiment should be simple enough that cause-and-effect relationships can be easily understood. If we include too many variables in a test, it will be hard to learn about what exactly caused the shift in the behavior.
This is one of the reasons large-scale redesigns are problematic. Even when the results are in the right direction, they fail to add any significant learning. This isn’t to say you should do redesigns if needed, but test a few of the strongest hypotheses around redesign first.
What if you can’t find the reason why it’s working?
What happens when a particular thing works and improves conversion, but you aren’t able to find why? It shouldn’t stop you from reaping the benefits.
Google tested multiple variations of the color blue until they found the perfect shade of blue to increase conversions at Google. From the Guardian,
"About six or seven years ago, Google launched ads on Gmail," Google UK's managing director Dan Cobley explained. "In our search we have ads on the side, little blue links that go to other websites: we had the same thing on gmail. But we recognised that the shades of blue in those two different products were slightly different when they linked to ads.
"In the world of the hippo, you ask the chief designer or the marketing director to pick a blue and that's the solution. In the world of data you can run experiments to find the right answer.
"We ran '1%' experiments, showing 1% of users one blue, and another experiment showing 1% another blue. And actually, to make sure we covered all our bases, we ran forty other experiments showing all the shades of blue you could possibly imagine.
"And we saw which shades of blue people liked the most, demonstrated by how much they clicked on them. As a result we learned that a slightly purpler shade of blue was more conducive to clicking than a slightly greener shade of blue, and gee whizz, we made a decision.
"But the implications of that for us, given the scale of our business, was that we made an extra $200m a year in ad revenue."
It’s hard to find the reason why a particular shade of blue works. What we know is that it leads to $200 m in revenue a year, period.
With this, I will wrap this week’s post.
Sneak Peek into the Next Post
The next post “This is the Way” will cover
Steps to doing tests in the right manner
Using A/B tests as a tool of learning to be a super product/growth guy
Debates around A/B tests
Receive it in your inbox by subscribing if you haven’t



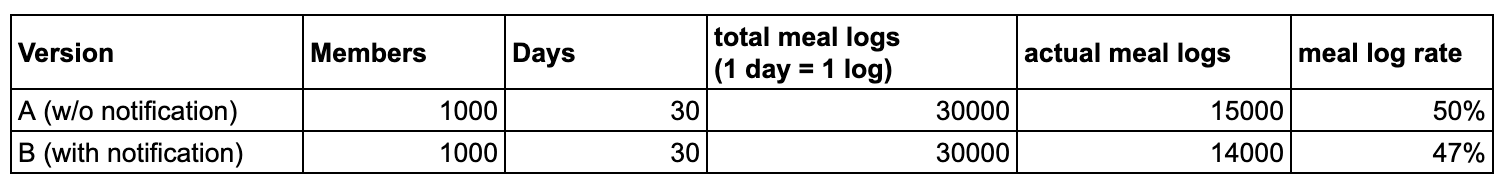
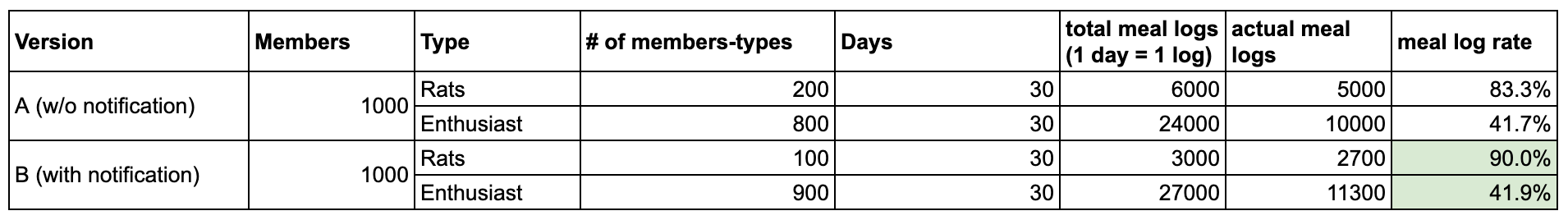

Cool Deepak.
Insightful.
Do also check your inbox and mail.